











'%3e%3cg%20transform='translate(0,256)%20scale(0.1,-0.1)'%20fill='black'%20stroke='none'%3e%3cpath%20d='M394%201681%20c-49%20-22%20-97%20-78%20-113%20-130%20-15%20-52%20-15%20-490%200%20-542%2016%20-52%2064%20-108%20113%20-130%2035%20-16%2068%20-19%20234%20-19%20277%200%20272%20-5%20272%20240%20l0%20160%20-29%2032%20c-24%2027%20-36%2033%20-71%2033%20-35%200%20-47%20-6%20-71%20-33%20-28%20-31%20-29%20-36%20-29%20-132%20l0%20-100%20-110%200%20-110%200%200%20220%200%20220%20170%200%20c129%200%20178%204%20199%2014%2066%2035%2066%20137%200%20172%20-22%2011%20-73%2014%20-221%2014%20-166%200%20-199%20-3%20-234%20-19z'/%3e%3cpath%20d='M1071%201686%20c-49%20-27%20-50%20-37%20-51%20-404%200%20-372%202%20-386%2055%20-410%2033%20-15%2057%20-15%2090%200%2045%2020%2055%2055%2055%20188%20l0%20120%20120%200%20c197%200%20200%204%20200%20260%200%20197%20-6%20226%20-55%20248%20-38%2017%20-382%2016%20-414%20-2z%20m269%20-246%20l0%20-60%20-60%200%20-60%200%200%2060%200%2060%2060%200%2060%200%200%20-60z'/%3e%3cpath%20d='M1711%201686%20c-48%20-27%20-50%20-41%20-51%20-359%200%20-324%202%20-342%2058%20-401%2052%20-56%2091%20-66%20257%20-66%20172%200%20210%2011%20262%2075%2051%2061%2054%2091%2051%20413%20l-3%20294%20-33%2029%20c-59%2053%20-140%2029%20-162%20-49%20-5%20-21%20-10%20-150%20-10%20-299%20l0%20-263%20-110%200%20-110%200%200%20280%20c0%20195%20-4%20287%20-12%20305%20-22%2048%20-88%2068%20-137%2041z'/%3e%3c/g%3e%3c/g%3e%3c/mask%3e%3c/defs%3e%3cg%20fill='%23ffffff'%3e%3crect%20x='74'%20y='74'%20width='364'%20height='364'%20rx='28'%20mask='url(%23rgpu-ring)'/%3e%3crect%20x='128'%20y='128'%20width='256'%20height='256'%20mask='url(%23rgpu-inner)'/%3e%3crect%20x='117'%20y='42'%20width='22'%20height='64'%20rx='11'/%3e%3crect%20x='160'%20y='42'%20width='22'%20height='64'%20rx='11'/%3e%3crect%20x='202'%20y='42'%20width='22'%20height='64'%20rx='11'/%3e%3crect%20x='245'%20y='42'%20width='22'%20height='64'%20rx='11'/%3e%3crect%20x='288'%20y='42'%20width='22'%20height='64'%20rx='11'/%3e%3crect%20x='330'%20y='42'%20width='22'%20height='64'%20rx='11'/%3e%3crect%20x='373'%20y='42'%20width='22'%20height='64'%20rx='11'/%3e%3crect%20x='117'%20y='405'%20width='22'%20height='64'%20rx='11'/%3e%3crect%20x='160'%20y='405'%20width='22'%20height='64'%20rx='11'/%3e%3crect%20x='202'%20y='405'%20width='22'%20height='64'%20rx='11'/%3e%3crect%20x='245'%20y='405'%20width='22'%20height='64'%20rx='11'/%3e%3crect%20x='288'%20y='405'%20width='22'%20height='64'%20rx='11'/%3e%3crect%20x='330'%20y='405'%20width='22'%20height='64'%20rx='11'/%3e%3crect%20x='373'%20y='405'%20width='22'%20height='64'%20rx='11'/%3e%3crect%20x='42'%20y='117'%20width='64'%20height='22'%20rx='11'/%3e%3crect%20x='42'%20y='160'%20width='64'%20height='22'%20rx='11'/%3e%3crect%20x='42'%20y='202'%20width='64'%20height='22'%20rx='11'/%3e%3crect%20x='42'%20y='245'%20width='64'%20height='22'%20rx='11'/%3e%3crect%20x='42'%20y='288'%20width='64'%20height='22'%20rx='11'/%3e%3crect%20x='42'%20y='330'%20width='64'%20height='22'%20rx='11'/%3e%3crect%20x='42'%20y='373'%20width='64'%20height='22'%20rx='11'/%3e%3crect%20x='405'%20y='117'%20width='64'%20height='22'%20rx='11'/%3e%3crect%20x='405'%20y='160'%20width='64'%20height='22'%20rx='11'/%3e%3crect%20x='405'%20y='202'%20width='64'%20height='22'%20rx='11'/%3e%3crect%20x='405'%20y='245'%20width='64'%20height='22'%20rx='11'/%3e%3crect%20x='405'%20y='288'%20width='64'%20height='22'%20rx='11'/%3e%3crect%20x='405'%20y='330'%20width='64'%20height='22'%20rx='11'/%3e%3crect%20x='405'%20y='373'%20width='64'%20height='22'%20rx='11'/%3e%3c/g%3e%3c/svg%3e)

Robotics training
Caltech Robotics Lab
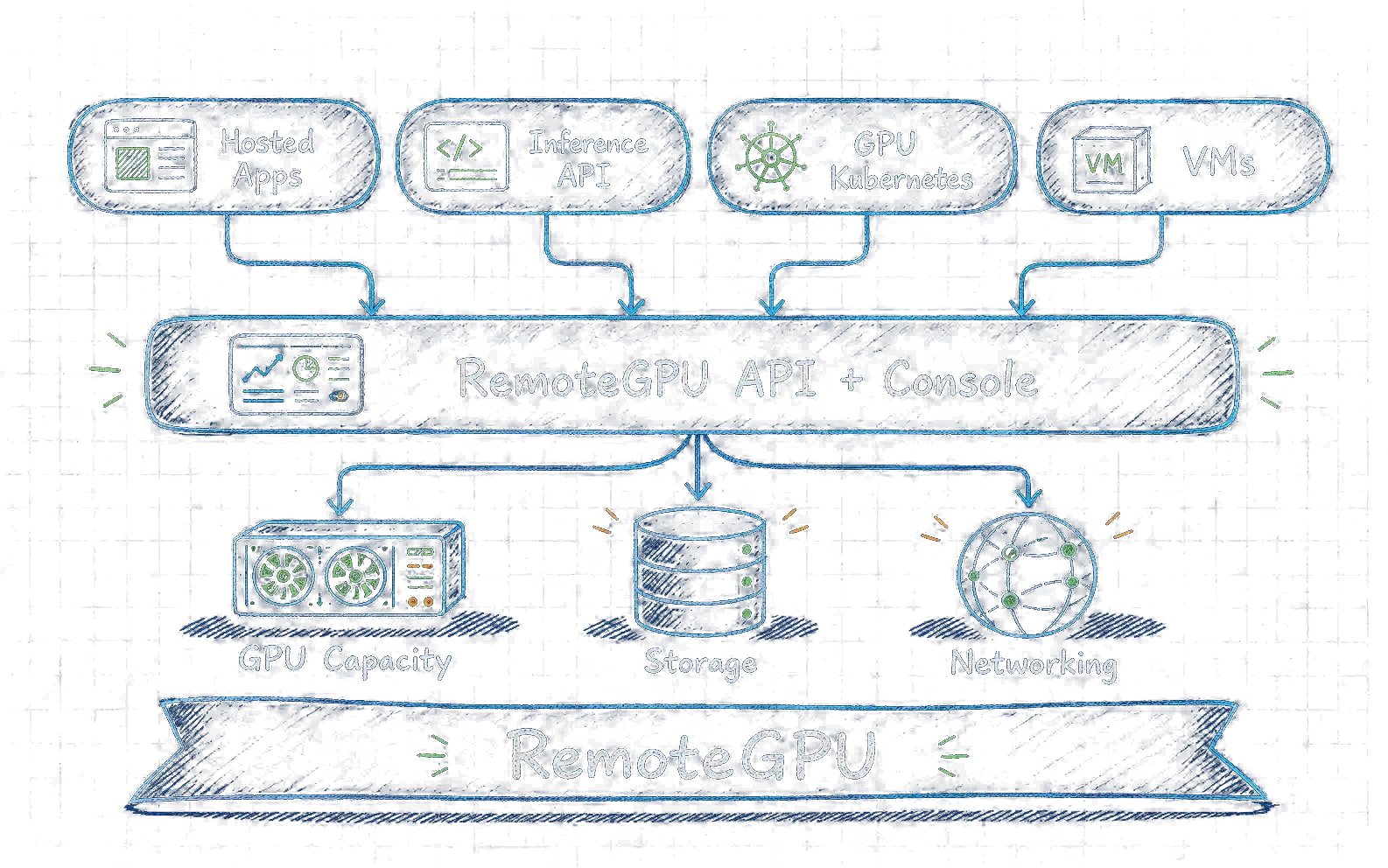
For the robotics collaboration, RemoteGPU gives Caltech researchers elastic GPU capacity for policy training, simulation sweeps, and evaluation runs. The team can move between lab experiments and repeatable cloud jobs without waiting on local machines or rebuilding the same runtime for every research cycle.

